Wie täusche ich bei vergleichenden Trenddarstellungen?
Das Beispiel aus Leibigers Dresdner Präsentation¹
Jürgen Leibiger gibt in seiner Präsentation zum Ökonomie-Widerstreit¹ — wohl in redlicher Absicht — auf Seite 13 (ohne Quellenangabe) eine täuschende Darstellung zur Lohnentwicklung mit einem sichtbar „starken Zurückbleiben” der Reallohn-Entwicklung 1948-2013 hinter dem Produktivitätsverlauf wieder:
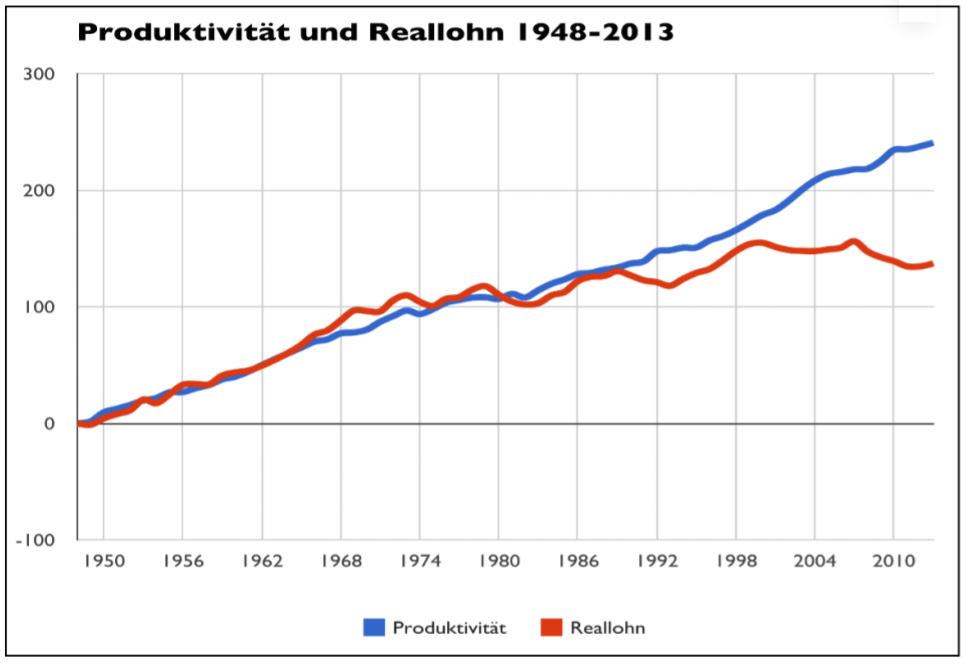
Ich erinnerte mich an einige Ratschläge aus dem Fach Statistik, besonders Hinweise auf die Tricks, mit denen andere Aussagen nahegelegt werden sollen, als in den Daten stehen. Objektiv liegen statistische Daten nur im Original vor, z.B. als Zeitreihen in Excel-Tabellen. In unserem Beispiel handelt es sich um die Produktivitätsreihe, die Nominallohnreihe und eine Preisindexreihe. Entgegen verbreiteter Ansicht ist jede daraus gewonnene Grafik in irgendeiner Weise manipulativ. Hier sind vier Tricks:
Bei Reallöhnen besteht der erste Trick in der Auswahl des Anfangsdatums, um damit die Reallohnreihe zu errechnen. Je nachdem, ob an dieser Stelle der Nominallohnreihe eine Delle nach unten oder eine Delle nach oben getroffen wird, sind auch die weiteren Reallohnangaben überhöht oder unterschätzt.
Der zweite Trick besteht darin, an der senkrechten Achse einfach die Kurven bei ihrem niedrigsten Wert beginnen zu lassen (ohne Kennzeichnung, dass da ein unterer Bereich weggelassen wurde) oder umgekehrt bei einer unberechtigten Null zu starten. Natürlich kann der Reallohn 1948 nicht 0 gewesen sein und auch die Produktivität nicht 0. Stellen wir uns die Grafik mit Vorgeschichte mal fiktiv (und vereinfacht) so vor: Abb. 2

Ein dritter Trick ist die Transformation in einen einzigen Wertebereich. Da zu jedem Zeitpunkt die Produktivität deutlich über dem entsprechenden Nominallohn liegen muss (kapitalistische Überlebensbedingung) und der Anfangswert der Reallohnreihe genau gleich dem ersten Nominallohn sein muss, sollte der Wertebereich der Reallöhne unter dem der Produktivitäten liegen. Dann kann der Anfangswert der Reallohnkurve aber nicht auf gleicher Höhe wie der Anfangswert der Produktivitätskurve liegen. Sowohl in Abb. 1 wie auch in Abb. 5 wurde der Wertebereich der Reallöhne in den Wertebereich der Produktivitäten entsprechend hoch transformiert — eine klare Manipulation.
Aber der Trick mit der gemeinsamen senkrechten Skala ist noch suggestiver.
Das Prinzip
Wie das funktioniert, möchte ich an einem einfachen Beispiel zeigen, das hypothetische Preise für Gold und Silber vergleicht. Wir wollen hier annehmen, der Goldpreis sei immer genau doppelt so hoch gewesen wie der Silberpreis, bei gleichmäßiger Entwicklung. Dann erhalten wir mit dem Ein-Skalen-Trick:
Abb. 3:Korrektur an einem anderen Beispiel
Die Quelle für Leibigers Abbildung konnte ich nicht finden,
aber ich fand eine ähnliche Grafik²:
Abb. 5:
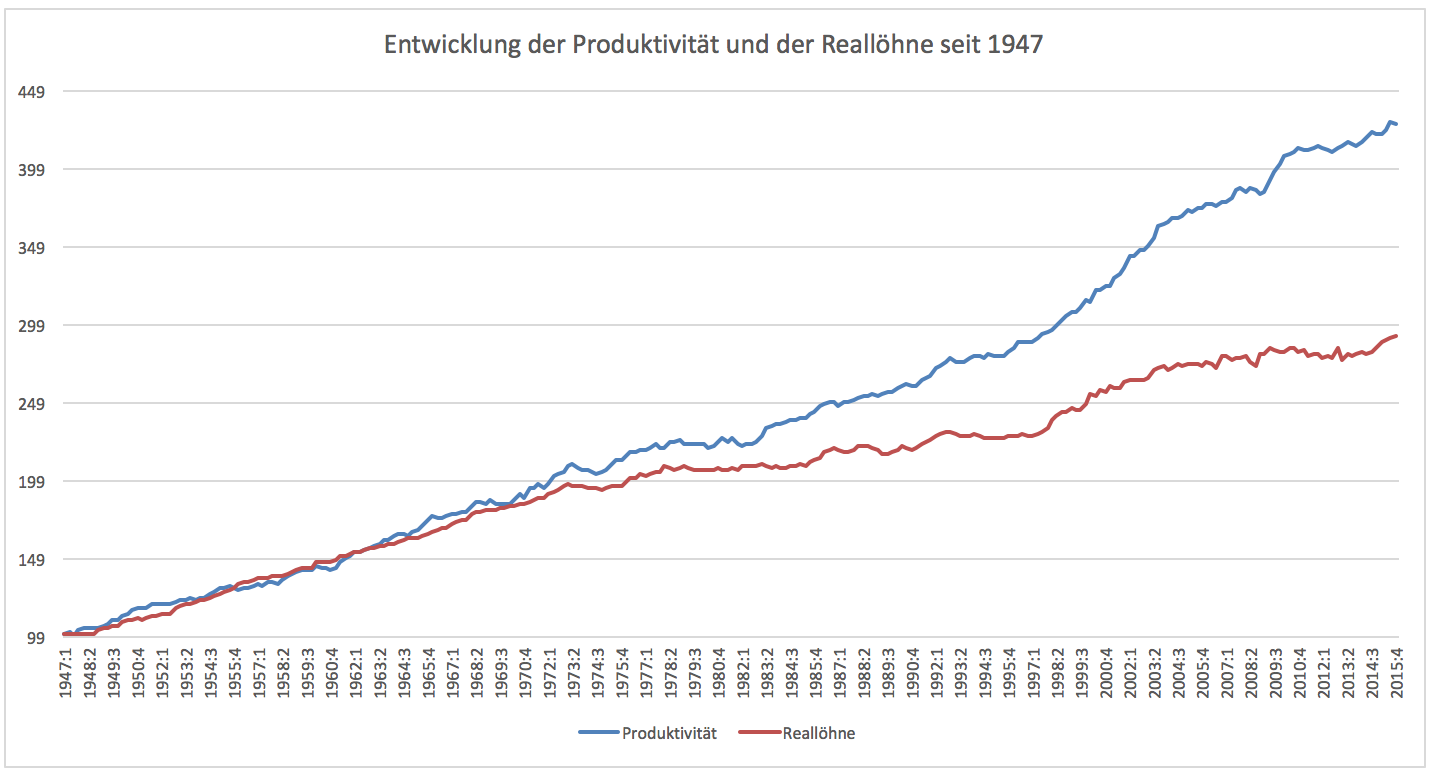
Ich habe mal die Reallohn-Kurve angepasst, indem ich die Endpunkte aufeinandergelegt und die rechte Skala angeglichen habe. Es war stundenlange Arbeit: Manuelles Herausarbeiten je eines Bildes nur mit der blauen bzw. nur mit der roten Kurve, Einfügen der linken Skala auch rechts im roten Bild, Verzerren des roten Bildes, bis der Endpunkt die Höhe des blauen Endpunkts im Original erreicht, und schließlich transparentes Zusammenkopieren der beiden Bilder.
Abb. 6:
 Schon lassen sich die gleichen zugrundeliegenden Daten
(die gleichen Zahlenreihen für Produktivität und Reallöhne,
und natürlich unsichtbar auch für Nominallöhne und Preisindizes)
ganz anders interpretieren:
„Die Reallöhne waren der Produktivität davongeeilt
und haben sich nun wieder angeglichen.”
Gültig bleibt die Aussage: „Die Reallöhne stiegen
zuletzt relativ zur Produktivität weniger stark”,
unregelmäßig, fast unmerklich.
Schon lassen sich die gleichen zugrundeliegenden Daten
(die gleichen Zahlenreihen für Produktivität und Reallöhne,
und natürlich unsichtbar auch für Nominallöhne und Preisindizes)
ganz anders interpretieren:
„Die Reallöhne waren der Produktivität davongeeilt
und haben sich nun wieder angeglichen.”
Gültig bleibt die Aussage: „Die Reallöhne stiegen
zuletzt relativ zur Produktivität weniger stark”,
unregelmäßig, fast unmerklich.
Doch auch das ist fehlerhaft suggestiv. Die Endpunkte beider Kurven sind nicht repräsentativ für den durchschnittlichen Verlauf. Man müsste beide Durchschnitte auf gleiche Höhe legen und eine entsprechende rechte Skala bilden. Da ich über die Daten selbst nicht verfüge, kann ich das hier nicht zeigen. Auch müsste ich nach der Skalen-Eigenschaft fragen: Muss ich das arithmetische Mittel oder das geometrische Mittel nehmen? Doch welcher Statistiker macht sich schon diese Arbeit?
Zweifelt „sich öffnende Scheren” in populären Statistiken ruhig mal an — aber schließt sie auch nicht ganz aus! Möglich wären sie schon — aber seltener.